
the speed of Perl file finders
Sometimes you need to walk a directory tree, pick out files, and do stuff. If
you’re working in the shell, you can use find — at least if you have GNU
find. Those other finds… shudder.
If you’re in Perl, of course, there’s more than one way to do it! Today’s question is, how do they perform?
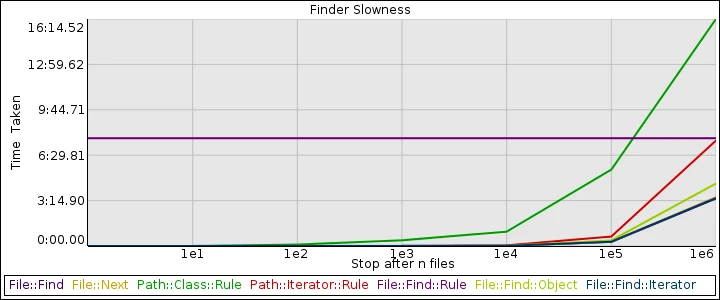
This charts the time required to find every entity under a root directory. The y axis is the amount of time it took. The x axis is the number of files the iterator was allowed to find before being told it was done. Note: the x axis is logarithmic. The first tick is finding 1 file, the next 10, then 100, then 1,000, and so on.
So, what’s going on? Here’s a brief run down.
First, there was File::Find. It came with Perl 5, and it has just the kind of interface you’d expect. It’s totally workable, but weird. As you can see, though, it’s among the fastest things we’ve got.
Around 2002, Richard Clamp released File::Find::Rule, which has a really nice, convenient interface. (Maybe it’d be even better if its objects were immutable, but I’m pretty happy with it as it stands!) There’s just one problem. It implements its iterator in terms of slurp instead of the other way around. Oops. That’s why it’s got that horizontal line. (Confession: when regenerating these data, I only generated a few of FFR’s points, to save time. I promise: the fluctuations in previous runs were uninteresting and tiny.) No matter how many files you are actually going to pull out of its iterator, it gets them all first. This has made it totally unusable for most of the things I’d use it for, which is a bummer.
I complained about this, probably way too much, in earshot of David Golden, and this may have contributed to his creation of Path::Class::Rule, which has a very File::Find::Rule-like interface, but finds files lazily, rather than eagerly, and so it’s much more efficient at searches across large trees that might terminate early. It even gives back results as Path::Class objects, which are nice and convenient. Unfortunately, they’re also really slow for a number of reasons. David Golden and Vincent Pit and Zefram have all done bits of work that could really speed them up, but until that’s all released, Path::Class::Rule is a dog on larger finds. Once it hits a bit over 100k files, it’s slower than File::Find::Rule, and gets even slower at an alarming rate.
When he found out how slow Path::Class::Rule could get, David Golden went back to the drawing board and produced Path::Iterator::Rule, which is just like Path::Class::Rule, but gives you strings instead of objects. It’s much faster than Path::Class::Rule. There’s clearly some room for improvement, because its curve doesn’t quite match File::Find’s yet, but that may be at least in part because of its default options. I didn’t spend much time profiling with custom options.
Finally, I’ve also included Andy Lester’s File::Next, which I also like quite a bit. I tend to prefer the Rule modules because it’s so easy to set up a search, but File::Next is what I’ve used for years when File::Find::Rule’s eager slurping would make it impossible for me to use. It may be that now I’m a Path::Iterator::Class user forever, but File::Next is still A-OK with me. If you can’t see File::Next’s line, it’s because it’s almost exactly the same data as File::Find.
Updates
I regenerated the chart on 2013-01-23 13:35, using data at 1e0 through 1e6 rather than the previous odd set. I also added two new libraries: File::Find::Object and File::Find::Iterator, of which I have used neither.
I did not time File::Find::Declare. It doesn’t provide lazy iteration, so I would never use it.
I did not time File::Find::Match. It doesn’t provide lazy iteration, so I would never use it.
I did not time File::Find::Node. It doesn’t provide lazy iteration, so I would never use it. It does allow forking of children to handle subtrees, which is nice, though.
I did not time File::Find::Wanted. It’s just a thin bit of sugar for File::Find.
The Source
You can find the source for generating most of this, and some of the states of my result files in my perl-file-finder-speed repo.